Automating University Admissions: How AutoEnrol Works in 5 Minutes
How AutoEnrol reads applicant documents, evaluates them against your institution's rules, and produces a defensible recommendation in under a minute, with a full audit trail your team controls.
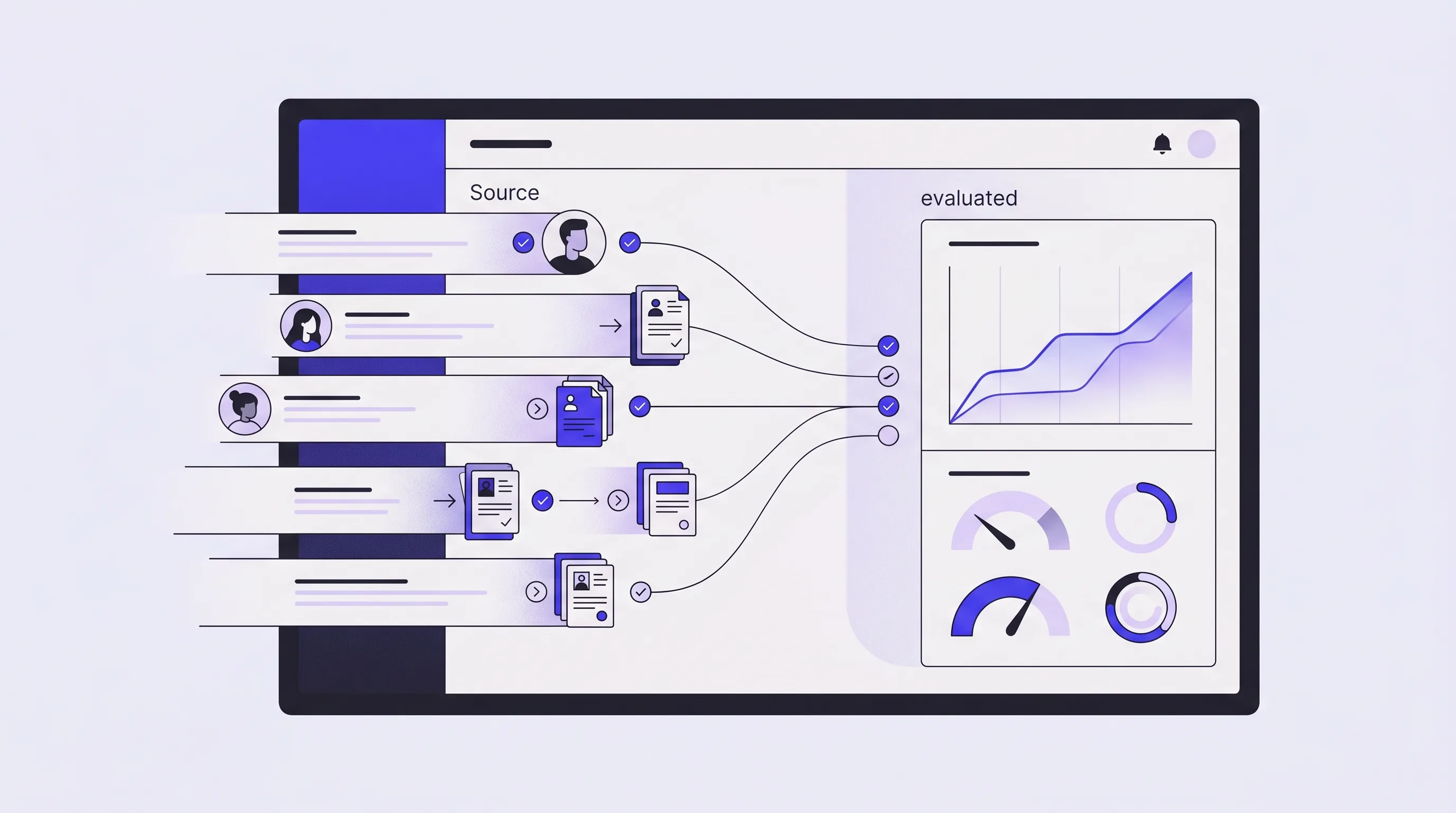
A senior assessor at an Australian university opens an international application on Monday morning. The applicant is from Vietnam, applying for a postgraduate engineering programme. There are seven documents to work through: a transcript in Vietnamese with an English translation that doesn't quite match, an IELTS certificate, a passport, two reference letters, a CV, and a statement of purpose. The transcript uses a 10-point scale. The applicant's institution isn't on the standard NOOSR Section 1 list, but it might fall under Section 2 once you check the country guidance. The IELTS scores are above the programme threshold but below the threshold for one of the embedded English requirements.
She works through it carefully. Forty-five minutes later, she has a recommendation. It's defensible, it's documented, and it's correct.
That same applicant, an hour later, runs through AutoEnrol. The recommendation appears in under a minute. It is the same recommendation she would have made. The audit trail behind it shows every rule that fired, every document that was read, and every data point that was extracted, pointing back to the exact line in the source document. She reviews it. She approves it. She moves on to the next applicant.
That is the whole product, in one paragraph. The rest of this piece explains how.
Stage one: the language model reads
The first job is extraction. AutoEnrol takes whatever the applicant has uploaded, in whatever language, in whatever format, and turns it into structured data the rest of the system can work with.
This is the kind of job language models are genuinely good at. A well-tuned extraction pipeline can read a Vietnamese transcript, an Indian mark sheet, a Nigerian WAEC certificate, a Chinese gaokao result, or an American GPA, and pull out what's actually there. It handles scanned documents, handwritten annotations, inconsistent layouts, bilingual headers, and country-specific quirks.
This part of the system has had the most engineering time spent on it of anything in the product. Anyone can plug into a language model. Getting reliable, structured, auditable extraction out of the other end is a different problem. We've built our own benchmark dataset of 800 labelled applications, with ground-truth answers verified by admissions professionals, and we test every change to the extraction pipeline against it. On that benchmark, extraction accuracy sits at 99.7%.
That number does a lot of work, and it's worth being honest about what drives the 0.3%. Almost all of it is poor-quality source material. A photograph of a transcript taken at an angle under poor lighting. A scan where the resolution is too low to read small print. A document that has been photocopied so many times that the text has degraded. When the extraction pipeline hits one of these, it doesn't guess. It flags the field as low-confidence and routes the application to human review, with the specific document and the specific field highlighted. The 0.3% isn't silent errors. It's the system knowing when it needs a person.
What the extraction produces is structured. The applicant's name, date of birth, country of citizenship, qualifications, grades, English language scores, document types and dates, all parsed into clean fields against a defined schema. The messy human document on the left, the structured data on the right. From here on, the rest of the system is working with the data, not the document.
Stage two: your rules decide
The structured data is then evaluated against your rules.
This is the part that matters most, and it's the part most often misunderstood. AutoEnrol does not decide who gets in. AutoEnrol evaluates the rules your institution has written, against the data extracted from the application, and produces a recommendation based on what those rules say. The decision logic is not a language model making a judgement. It is a logic tree, written in plain English by your admissions team, translated into Boolean rules, approved by your team, and then evaluated deterministically. Same inputs produce the same outputs. Every time.
The rules are yours. You write them. You approve them. You edit them. You version them. If your equivalencies for Vietnamese qualifications change next intake, you update the rule and the change is live. If a senior assessor disagrees with how a rule reads in plain English, they edit it directly. Nothing goes live without your sign-off.
Getting your rules into the system is itself a piece of work, and we don't pretend otherwise. Most admissions teams have their rules scattered across handbooks, country guides, spreadsheets, and the heads of senior staff. Onboarding involves bringing all of that into one place. AutoEnrol's Onboarding Agent drafts rule translations from your handbook. Your admissions team approves, edits, or rejects. The approved rules make the decision.
For a lot of institutions, this is the most valuable thing the engagement produces, whether or not the automation is ever switched on. Several teams we've worked with described it as the first time they had their international admissions logic written down cleanly, in one place, in a form everyone could read. One Australian admissions director put it as wanting to have rules "nicely documented in a single database." That single database, populated and approved by his team, is what AutoEnrol's logic tree runs on.
Stage three: validation and the audit trail
The output of stage two is a recommended decision. Unconditional offer, conditional offer, refer to faculty, or reject, with the rationale written in plain English: which rules fired, which documents supported them, where in the documents the supporting data sits.
The word "recommended" matters. The decision belongs to your assessor. They look at the recommendation, they check the audit trail, they validate or override, and they sign off. This is not AutoEnrol making decisions and your team rubber-stamping them. This is your team making decisions faster, with better information, and with every step recorded.
The audit trail is the second thing that gets understated when people first encounter the product. Every decision the system processes leaves behind a complete record: what was extracted from the documents, which rules were evaluated, which fired, which didn't, why the recommendation came out the way it did, and exactly where in the source documents the supporting evidence sits. Click any decision, see exactly where it came from. That trail is what makes the system defensible to a registrar, an internal auditor, an external auditor, or a regulator asking how a decision was reached.
For decisions that the rules can't cleanly resolve, the system refers to a human. This is not a failure. This is the system doing what it should: handling the high-volume, well-defined work, and routing the genuinely complex cases to the people who should be looking at them. Your senior assessors spend more of their time on the work that requires their judgement, and less of their time on transcript verification.
What it isn't
A few quick clarifications, because some of these come up constantly.
AutoEnrol is not a Student Information System. It does not hold student records long-term, manage enrolments, or replace anything in the SIS layer. It integrates with whichever SIS or CRM you use (StudyLink, Salesforce, Microsoft Dynamics, Banner, ESIS, SharePoint) and the applicant data flows through.
It is not a CRM. It does not manage the recruitment funnel or applicant communications.
It is not a chatbot. It does not communicate with applicants.
It is not a credential evaluator in the WES or ECE sense. It does not issue external certifications.
It is not a general-purpose AI tool. The decision step does not involve a language model making a judgement. The category we are building toward is admissions decision infrastructure: the institution's operating system for converting policy into repeatable decisions.
Where this leaves your team
The most common question we get from admissions directors, when they first see the product, is what happens to their team.
The honest answer is that the work changes. The first-pass document review, the GPA conversion, the country list lookups, the IELTS-to-PTE equivalency check: that work is done by the system, in seconds, with full audit. What remains is the work that actually requires the assessor: the borderline cases, the documents that don't quite fit any rule, the policy questions that need a senior judgement, the quality assurance on what the system has produced. The throughput goes up. The complexity of the work that stays in human hands goes up too.
But more than that, it frees up time and brainpower for admissions staff to design strategy, provide better reporting, and take a leading role in driving the institution's goals, whether that's more students, different students, or lower-risk students.
This is not a story about replacing assessors. It's a story about giving them their day back. The boring 80% gets handled. The interesting 20% is what your team gets to spend their time on.
That's how AutoEnrol works.